This is the third of a multipart series that explains the basics of btrfs’s on-disk format.
At the end of this series, we’ll have a program that can print out
the absolute path of every regular file in an unmounted btrfs filesystem
image without external libraries or ioctl(2) calls.
Example code is available here.
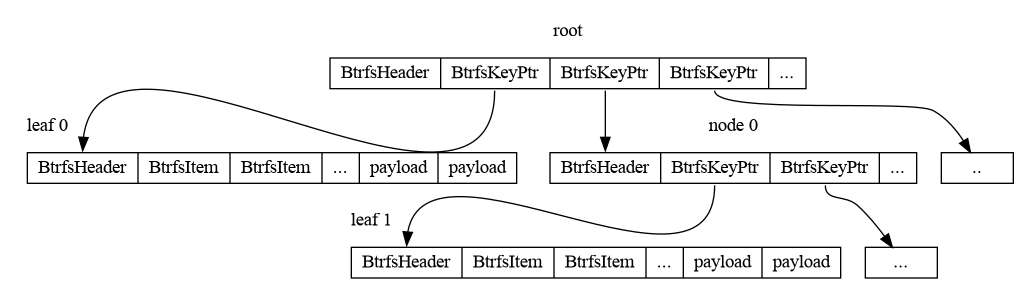
As explained in part 2, btrfs stores nearly everything on-disk in B-trees. And as promised, I’ll now describe the B-tree data format. First, an example tree:
Each node in a btrfs B-tree is prefixed with a header. The header
records the node’s “level”. Level 0 means the node is a leaf node and
stores a payload. Level > 0 means the node is an internal node and
stores pointers to children nodes. The header also stores the number of
“items” the node contains where an “item” is either a pointer to child
node if level > 0, else, information on where to find
the payload in the node. Recall that each item in a node is sorted by
the associated BtrfsKey which allows for efficient binary
searches. There’s also some other data but it’s not too important to
us.
In our example, root and node 0 contain
BtrfsKeyPtrs because they’re not leaf nodes.
leaf 0 and leaf 1 contain
BtrfsItems because they are leaf nodes.
Now that we understand how trees are laid out on disk, let’s process the rest of the chunk tree.
First, let’s define the necessary structures:
#[repr(C, packed)]
#[derive(Copy, Clone)]
pub struct BtrfsHeader {
pub csum: [u8; BTRFS_CSUM_SIZE],
pub fsid: [u8; BTRFS_FSID_SIZE],
pub bytenr: u64,
pub flags: u64,
pub chunk_tree_uuid: [u8; BTRFS_UUID_SIZE],
pub generation: u64,
pub owner: u64,
pub nritems: u32,
pub level: u8,
}
#[repr(C, packed)]
#[derive(Copy, Clone)]
pub struct BtrfsKeyPtr {
pub key: BtrfsKey,
pub blockptr: u64,
pub generation: u64,
}
#[repr(C, packed)]
#[derive(Copy, Clone)]
pub struct BtrfsItem {
pub key: BtrfsKey,
pub offset: u32,
pub size: u32,
}Note that BtrfsItem::offset is the offset from the
end of the associated BtrfsHeader that we can find
the payload for the BtrfsItem.
Although not strictly necessary, we also define
BtrfsNode and BtrfsLeaf as the following:
#[repr(C, packed)]
#[derive(Copy, Clone)]
pub struct BtrfsNode {
pub header: BtrfsHeader,
// `BtrfsKeyPtr`s begin here
}
#[repr(C, packed)]
#[derive(Copy, Clone)]
pub struct BtrfsLeaf {
pub header: BtrfsHeader,
// `BtrfsItem`s begin here
}We don’t need these structure definitions because all it tells us is
that every node in the on-disk B-tree starts with
BtrfsHeader. After parsing the header and reading
BtrfsHeader::level, we can infer what follows the
header.
To walk any tree, we need to start at the root node. The superblock contains the logical offset the chunk tree root lives at. To read it:
fn read_chunk_tree_root(
file: &File,
chunk_root_logical: u64,
cache: &ChunkTreeCache,
) -> Result<Vec<u8>> {
let size = cache
.mapping_kv(chunk_root_logical)
.ok_or_else(|| anyhow!("Chunk tree root not bootstrapped"))?
.0
.size;
let physical = cache
.offset(chunk_root_logical)
.ok_or_else(|| anyhow!("Chunk tree root not bootstrapped"))?;
let mut root = vec![0; size as usize];
file.read_exact_at(&mut root, physical)?;
Ok(root)
}where chunk_root_logical is
BtrfsSuperblock::chunk_root.
Walking the actual tree looks like a traditional recursive tree-walking algorithm:
fn read_chunk_tree(
file: &File,
root: &[u8],
chunk_tree_cache: &mut ChunkTreeCache,
superblock: &BtrfsSuperblock,
) -> Result<()> {
let header = tree::parse_btrfs_header(root)
.expect("failed to parse chunk root header");tree::parse_btrfs_header is a simple helper function
that extracts the BtrfsHeader out of root and
returns a reference to the header.
// Level 0 is leaf node, !0 is internal node
if header.level == 0 {
let items = tree::parse_btrfs_leaf(root)?;If we’re at level 0, we know we’re looking at a leaf node. So we use
tree::parse_btrfs_leaf to extract the
BtrfsItems.
for item in items {
if item.key.ty != BTRFS_CHUNK_ITEM_KEY {
continue;
}We skip anything that isn’t a chunk item. The chunk tree also
contains BTRFS_DEV_ITEM_KEYs which help map physical
offsets to logical offsets. However, we only need chunk items for our
purpose so we skip everything else.
let chunk = unsafe {
// `item.offset` is offset from data portion of `BtrfsLeaf` where
// associated `BtrfsChunk` starts
&*(root
.as_ptr()
.add(std::mem::size_of::<BtrfsHeader>() + item.offset as usize)
as *const BtrfsChunk)
};As mentioned earlier, BtrfsItem::offset is the offset
from the end of the BtrfsHeader. The above code
does the proper math to pull out the BtrfsChunk associated
with the current item.
chunk_tree_cache.insert(
ChunkTreeKey {
start: item.key.offset,
size: chunk.length,
},
ChunkTreeValue {
offset: chunk.stripe.offset,
},
);
}Finally, we add the chunk entry into our chunk tree cache.
} else {
let ptrs = tree::parse_btrfs_node(root)?;
for ptr in ptrs {
let physical = chunk_tree_cache
.offset(ptr.blockptr)
.ok_or_else(|| anyhow!("Chunk tree node not mapped"))?;
let mut node = vec![0; superblock.node_size as usize];
file.read_exact_at(&mut node, physical)?;
read_chunk_tree(file, &node, chunk_tree_cache, superblock)?;
}
}If we see level != 0, we know we’re looking at an
internal node. So we use the tree::parse_btrfs_node helper
to parse an internal node. Once we have the BtrfsKeyPtrs,
we read the node the key points to and recursively call
read_chunk_tree.
Ok(())
}If we haven’t errored out by the end, it means we successfully walked the chunk tree.
Now that we’ve loaded the entire chunk tree into our cache, we can move onto walking the trees that contain the information we actually care about. In the next post, we’ll extract the filesystem tree root from the root tree root.